Understanding Apache Spark runtime architecture

Apache Spark is a popular open-source distributed computing platform that is used for processing large amounts of data. It has a runtime architecture that is based on the concept of distributed computing, where data is divided into smaller chunks and distributed across a cluster of machines for parallel processing. This allows Spark to quickly and easily process large amounts of data in parallel, enabling efficient and scalable distributed computing. We will see the main components of the Spark runtime architecture and how they work together to enable distributed computing with Spark.
Main components of the Spark architecture
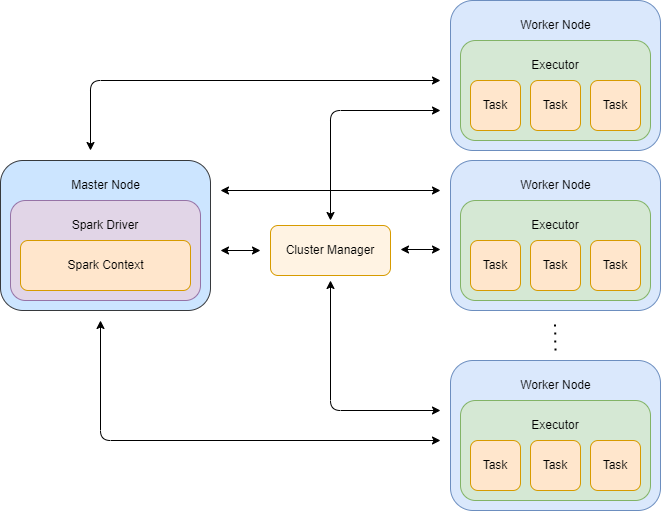
The main components of the Spark runtime architecture are the driver and the executors. The driver is the main program that runs on the master node of the cluster and is responsible for coordinating the execution of the parallel operations on the data. The executors are worker processes that run on the slave nodes of the cluster and are responsible for executing the tasks assigned to them by the driver.
In addition to the driver and executors, the Spark runtime architecture also includes several other components, such as the cluster manager, which is responsible for managing the allocation of resources across the cluster, and the scheduling algorithm, which is used to determine how tasks are assigned to executors. These components work together to enable efficient and scalable distributed computing with Spark.
Driver
The driver is the central component of the Apache Spark runtime architecture. It is responsible for running the user’s main function and creating the SparkContext, which is the main entry point for interacting with Spark. The driver also communicates with the cluster manager to acquire resources on the cluster and to schedule the execution of tasks on the worker nodes. It monitors the progress of tasks and provides status updates to the user, and it handles the flow of data between the various components of the application. In short, the driver coordinates the execution of a Spark application and is essential to its functioning.
Executors
In Spark, the executor is a process that runs on a worker node and is responsible for executing the tasks assigned to that node. It communicates with the driver process to request tasks and to report the progress of tasks, and it manages the execution of the tasks, including any data shuffles or other operations that are required. The executor also manages the memory and other resources on the worker node, including caching RDDs and other data in memory to improve performance. In short, the executor is responsible for executing the tasks assigned to a worker node and for managing the resources on the node to ensure that the application runs efficiently and effectively.
RDD or Resilient Distributed Dataset is a data structure that is used to represent the data that is processed by the executors. RDDs are immutable, which means that they cannot be modified once they are created. RDDs are also fault-tolerant, which means that they can be recovered from failures.
Cluster manager
In Spark, the cluster manager is a system that is responsible for managing the resources on a cluster of compute nodes, such as a cluster of computers in a data center. It is responsible for allocating resources to the various applications running on the cluster, and it monitors the health and status of the nodes in the cluster. Spark supports several different cluster managers and even includes a native cluster manager. The cluster manager is an important component of the Apache Spark runtime architecture, as it plays a key role in managing the resources on the cluster and in ensuring that the application runs efficiently and effectively.
How scheduling works in Spark
The scheduling process is the process by which the driver program divides the work of a Spark application into a set of tasks and assigns those tasks to the executors on the worker nodes in the cluster. The scheduling process is performed by the SparkContext, which coordinates with the cluster manager to acquire the resources needed to execute the application. Once the resources have been acquired, the SparkContext divides the work of the application into tasks and schedules those tasks for execution on the worker nodes.
All operations are represented as a Directed Acyclic Graph (DAG). A DAG is a representation of the sequence of operations that are performed in a Spark application. The DAG describes the dependencies between the different stages of the application, and it is used by the Spark runtime to determine the order in which the stages should be executed. The DAG is constructed from the operations that are performed on the data in the application, and each operation in the DAG corresponds to a stage in the application. The DAG is an important part of the Spark runtime architecture, as it allows Spark to process large amounts of data quickly and efficiently.
Tasks and stages
A task is a unit of work that is executed by an executor on a worker node in a cluster. A stage is a set of tasks that are executed together as part of a Spark application. Tasks and stages are an important part of the Spark runtime architecture, as they provide a way to divide the work of a Spark application into smaller, parallelizable units that can be executed efficiently on a distributed cluster of compute nodes. This allows Spark to process large amounts of data quickly and efficiently.
Transformations and actions
Transformations are operations that are applied to the data to create a new RDD. Transformations are lazy, which means that they are not executed immediately. Instead, they are added to the DAG.
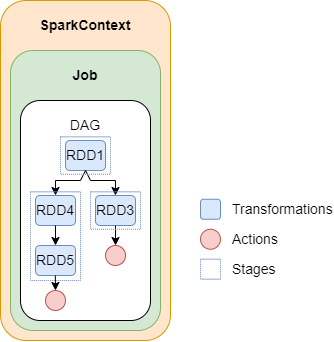
In Spark, transformations are operations that are applied to a dataset to create a new one. These operations are lazily executed, meaning that they are not performed until an action is called. This allows for more efficient processing, as Spark can optimize the sequence of transformations by grouping them and executing them in a single pass over the data. In general, transformations are used to manipulate and transform the data in a dataset, such as selecting specific columns, filtering rows, or performing calculations on the data.
In against, actions are operations that trigger the execution of the transformations and return results to the driver program. These operations allow the user to see the results of the transformations that have been applied to the dataset. In general, actions are used to collect the results of the transformations that have been applied to a dataset and return them to the driver program for further processing.
A stage typically consists of all the transformations that are applied to a dataset up until the next shuffle operation or action. This means that a stage typically ends with an action, as this triggers the execution of the transformations and causes the tasks in the stage to be executed.
Overall, the Apache Spark runtime architecture is designed to be highly modular and extensible, with a rich set of APIs and libraries that make it easy for developers to build powerful, scalable applications for big data processing and analysis. The various components of the runtime architecture work together to enable efficient, parallel execution of Spark applications on a distributed cluster of compute nodes.